Indeksowanie – to zapamiętanie informacji o stronie przez wyszukiwarkę żeby ta mogła wyświetlić stronę w wynikach wyszukiwania. W mowie potocznej stosuje się równie często formę zapożyczoną z j. ang. indexowanie.
Ale jeśli nie wystarcza Ci ta zwięzła definicja, czujesz że za tą niepozorną definicją kryje się coś więcej lub chcesz się dowiedzieć więcej o indeksowaniu w Google to zapraszam do dalszej lektury. A zaczniemy nietypowo, na początek rozprawmy się z tym trudnym słowem jakim jest indeksowanie i…
Znaczenia słowa “indeksowanie”
Rdzeń słowa pochodzi z łaciny index → indeks co oznacza palec wskazujący, spis, lista, wskaźnik, wykaz (źródło: Słownik Łacińsko-polski ). W języku polskim indeks to m.in alfabetyczny spis pojęć, terminów, nazwisk itp. przytoczonych lub omówionych w danej książce (źródło: Słownik Języka Polskiego). W słowniku angielskim również występuje podobna definicja, a także: a collection of information stored on a computer or on a set of cards, in alphabetical order – co tłumaczy się na: zbiór informacji przechowywanych w komputerze (albo na kartach), ułożonych alfabetycznie. (źródło: Cambridge Dictionary)
A więc indeksowanie będzie czynnością polegającą na tworzeniu lub uzupełnianiu spisu, listy (żeby nie powiedzieć indeksu). W znaczeniu informatycznym Wielki Słownik Języka Polskiego podaje wprost „indeksować – dodawać opisy, stworzone według określonych kryteriów, do bazy danych, ułatwiając przeszukiwanie…„
Indexować to zapożyczona/naśladowana pisownia z j. ang. (po ang. index / indexing), gdzie “x” jest zbieżne z łacińskim index. W polskich tekstach branżowych można spotkać oba warianty zapisu (szczególnie w SEO/IT), mimo że słownikowo po polsku poprawna forma to indeksowanie.
Dlaczego to słowo pasuje do wyszukiwarek?
W informatyce indeks to struktura pomocnicza w bazie danych, która przyspiesza wyszukiwanie – analogicznie do indeksu na początku (lub końcu) książki. Google również używa dokładnie tej metafory w swoich dokumentacjach “…Much like the index you’d find in the back of a book…” (źródło: Dokumentacja Google BigQuery) – fragment z dokumentacji bazy danych BigQuery.
Poprawnym więc będzie stwierdzenie, że wyszukiwarki poprzez indeksowanie budują ogromny spis treści Internetu, który pozwalają nam przeszukiwać go w szybki i wygodny sposób. Technicznie rzecz ujmując wyszukiwarka jest ogromną bazą danych (uzupełnianą przez roboty indeksujące) mapującą słowa, pojęcia i pytania na miejsca w Internecie.
Indeksowanie – jak to działa?
Omawiając ten temat skupimy się tylko na wyszukiwarce Google, jeżeli chcesz więcej dlaczego sprawdź ten artykuł: SEO – co to jest i jak działa? Proste wyjaśnienie – LetGrow SEO
Gdy Google wie już o naszej stronie – gdy znajdzie ją sam lub damy mu znać, że nasza strona gdzieś tam istnieje – to następnie (może, ale nie musi) stara się rozpoznać jej tematykę i ją zapamiętać. Google przechowuje informacje o setkach miliardów stron, jak więc w takim razie znajduje wyniki w ułamku sekundy? Nie może przecież za każdym razem przeglądać Internetu. Jest to sprytnie zrealizowane za pomocą zaawansowanych technologii. I nie jest to zwykłe mapowanie strona → skrót treści, a odwrócony indeks fraza kluczowa → lista adresów (źródło: Jak działa wyszukiwarka Google | Centrum wyszukiwarki Google | Documentation | Google for Developers)
Indeksowanie na podstawie przykładu
Gdy użytkownik wpisuje zapytanie “Ranking laptopów gamingowych” Google sprawdza po kolei wyniki dla każdego słowa z osobna:
Potem wchodzi na drugi poziom selekcji, Google nie daje się nabrać na same słowa. Może się zdarzyć, że sklep ma w menu “laptopy”, gdzieś w stopce słowo “ranking”, a w opisie myszki “gamingowa” – formalnie te słowa występują, ale to nie jest strona o rankingach laptopów gamingowych (i Google potrafi to zrozumieć). Dlatego Google sprawdza czy te elementy są ze sobą skorelowane i tworzą spójny temat. Dodatkowo Google rozpoznaje intencje, jeżeli padło słowo “ranking” to oczekujesz porównania i kryteriów (np.: model, cena opis, wydajność…)
Co robi algorytm?
Przecięcie (Intersection) – Google szuka części wspólnej. Szuka identyfikatorów dokumentów, które znajdują się jednocześnie na wszystkich trzech listach
Filtrowanie zbieżności – System odrzuca strony, które mają te słowa, ale nie są o tym temacie. Na tym etapie odpadnie np. sklep z elektroniką, który ma w menu „Laptopy”, w stopce „Ranking”, a w opisie myszki słowo „Gamingowa”. Bo w jego indeksie odwróconym te słowa są od siebie zbyt oddalone (tzw. positional index).
Weryfikacja intencji (Intent) – Ponieważ użyłeś słowa „Ranking”, Google zakłada, że użytkownik chce porównania i kryteriów wyboru, a nie tylko ogólnej informacji. Dlatego wyżej pokaże strony, które wyglądają jak ranking: mają listę modeli, parametry, plusy/minusy i język typowy dla porównań. Jeśli Twoja strona ich nie ma, wypada z głównego nurtu wyników, mimo że zawiera słowa kluczowe.
Jeżeli nie boisz się pojęć takich jak Kompresja czy przecięcie list to w tym fragmencie zagłębimy się w aspekty techniczne, ale uprzedzam, muśniemy zaledwie wierzchołek góry lodowej. Jeszcze tu jesteś? No to lecimy!
Fundament techniczny
Technicznym fundamentem nie jest jedna baza danych, lecz ogromny ekosystem rozproszony oparty na systemie plików Colossus (źródło: A peek behind Colossus Google file system) oraz o system zarządzania danymi strukturalnymi na skalę petabajtów i tysięcy serwerów Bigable (źródło: Bigtable: A Distributed Storage System for Structured Data)
To tam Google przechowuje surowe dane o miliardach dokumentów. Kluczem do prędkości jest jednak indeks odwrócony (inverted index), który działa jak gigantyczna tablica mieszająca. Gogle operuje na tzw. Posting Lists – listach identyfikatorów dokumentów DocID przypisanych do konkretnych tokenów reprezentujących słowa. Listy te są pofragmentowane na tysiące węzłów (z ang. nodes) – źródła podają że ten proces nazywa się sharding, co pozwala na równoległe wykonywanie operacji na zbiorach w milisekundach.
Komputery tak naprawdę nie rozumieją słów tylko przekształcają je na wektory (ang. vector) liczbowe i porównują je za pomocą różnych operacji matematycznych np.: odległość między wektorami. Na podobnej zasadzie działają modele językowe LLM (large language models) jak Gemini, Chat GPT czy Claude (źródło: The anatomy of a large-scale hypertextual Web search engine).
Mechanizm świeżości i aktualizacji przyrostowych Caffeine + Percolator
Za aktualność danych odpowiada architektura Caffeine oraz system Percolator, które umożliwiają przyrostowe (incremental) aktualizowanie indeksu.
Google Caffeine to nie pojedynczy program, lecz kompletna przebudowa fundamentów (architektury) systemu indeksującego Google. (źródło: Our new search index: Caffeine)
Percolator to konkretna warstwa technologiczna (system), która umożliwiła przejście na indeksowanie przyrostowe. Percolator to silnik pod maską Caffeine – system służący do zarządzania ogromnymi zbiorami danych, który potrafi wprowadzać małe, niezależne zmiany zamiast przetwarzać wszystko od nowa. (źródło: Large-scale Incremental Processing Using Distributed Transactions and Notifications)
Całość optymalizują algorytmy kompresji, takie jak Delta Encoding czy instrukcje procesora SIMD. Te dwa pojęcia to istny rdzeń prędkości Google – kiedy mówimy o miliardach stron, nawet najszybszy procesor nie dałby rady, gdyby musiał przeglądać wszystkie dane po kolei.
Delta encoding (kodowanie różnicowe, gap encoding) – sposób kompresji danych polegający na zapisie różnicy (delty) między poszczególnymi elementami zamiast zapisywania pełnych wartości (np. kolejne identyfikatory dokumentów DocID). Pozwala to na upakowanie większej ilości danych na mniejszej przestrzeni (mniej bitów) i przyspiesza ich przetwarzanie (mniej danych do przenoszenia i odczytu).
SIMD (Single Instruction, Multiple Data) – architektura procesora, pozwalająca w jednej instrukcji wykonywać instrukcje równolegle na wielu elementach danych naraz (np. na całym wektorze liczb) – co się ładnie spina z delta encoding. Procesory o architekturze SIMD są wykorzystywane do przyspieszania operacji masowych, takich jak porównywanie, filtrowanie czy przecinanie dużych list, ponieważ pozwala przetwarzać dane blokami zamiast element po elemencie.
Google łączy warstwę programową z warstwą sprzętową tak aby najoptymalniej jak tylko się da przetwarzać monumentalne ilości danych. Aczkolwiek np.: to źródło An Introduction to Information Retrieval potwierdza przytoczone powyżej definicje i mechanizmy stosowane w wyszukiwarkach jako klasa rozwiązań, ale nie przesądza, że Google używa dokładnie tej techniki o tej nazwie w aktualnej produkcji.
Wstawka od autora: Choć nigdy nie pracowałem z tymi konkretnymi narzędziami to miałem styczność z BigTable i projektowałem jako inżynier oprogramowania w Software House DevAndDeliver systemy rozproszone. A także zaimplementowałem komunikację asynchroniczną i synchroniczną między systemami rozproszonymi wykorzystując m.in rabbitmq, nestjs, rxjs. Posiadam też wiedzę w zakresie budowy procesorów zaczerpniętą z wykładów na Zachodniopomorskim Uniwersytecie Technologicznym w Szczecinie i jestem pasjonatem elektroniki.
Co to znaczy, że strona jest zaindeksowana?
W katalogu (indeksie) nie przechowuje się całych stron. Przechowuje się informacje o miejscu strony, jej opis i kilka dodatkowych informacji pozwalających na:
- stwierdzenie czy strona istnieje
- szybkie jej odnalezienie na podstawie zapytania (słowa lub pytania)
- określenie o czym jest strona i jaka treść się na niej znajduje
Indeks Google nie przechowuje całego Internetu. To że Google (precyzyjniej mówiąc googlebot) odwiedza naszą stronę nie jest równoznaczne z zaindeksowaniem strony. Odwiedziny są dopiero fragmentem procesu analizowania strony, w trakcie którego Google:
- wyciąga treść i atrybuty ze strony,
- analizuje temat i strukturę,
- porównuje stronę z innymi podobnymi (duplikaty/warianty),
- wybiera, co jest wersją główną (tzw. kanoniczną),
- następnie podejmuje decyzję, czy warto to trzymać w indeksie jako osobną pozycję.
To moment, w którym Google może zdecydować o NIE dodaniu strony do indeksu nawet jeżeli technicznie stronę pobrał Jeżeli jednak wynik analizy trafia do indeksu to możemy powiedzieć, że strona została zaindeksowan i Google zapisuje informacje o stronie w swoim katalogu (w duuuuuuuużej bazie danych).
Podsumowując, indeksowanie to efekt procesu analizy i decyzji czy dana strona zasługuje na pojawienie się wśród wyników wyszukiwania (na pojawienie się w indeksie)
Jak wyszukiwarka rozumie temat strony
Proces poznawania strony obejmuje analizę: treści (tekstu na stronie), kluczowych znaczników (np. H1-H6) i atrybutów takich jak elementy <title> i <meta name=”description” content=”…opis strony”> czy atrybutów „alt” obrazów.
Google nie publikuje jednej, aktualnej liczby czynników rankingowych i zwykle unika takich deklaracji. W oficjalnych materiałach pojawia się raczej sformułowanie, że trafność wyników jest wyliczana na podstawie setek czynników/sygnałów.
Wyciek z maja 2024 nie był kodem algorytmu, tylko wyciekiem dokumentacji wewnętrznego API. Publikowane analizy wskazują, że w tej dokumentacji zidentyfikowano 2 596 modułów oraz 14 014 atrybutów/cech (features/attributes) powiązanych z systemami rankingowymi bez informacji o wagach – bez pewności, co jest używane produkcyjnie.
Jednak daje nam to pewien obraz złożoności całego procesu. I niewielki wgląd w to co dziś się w kuluarach całego procesu.
Nagłówki H1-H6
Poświęćmy chwilę nagłówkom, jest to często spotykany problem podczas audytów SEO. HTML oferuje określone tagi nagłówków <h1>, <h2>, <h3>, <h4>, <h5> i <h6> (z odpowiednimi znacznikami zamykającymi). I o ile nic nam nie broni korzystać z nich dowolnie lub nawet nie użyć ich wcale to jednak praktyka SEO pokazuje, że warto zadbać o:
Intencja strony
Należy też zwrócić uwagę na ogólną intencję strony, na przykład czy treść strony odpowiednio określa to, że jest to konkretna strona nastawiona na sprzedaż (transakcyjna), czy jest to strona porównująca lub ranking, czy może jest to strona informacyjna albo nawigacyjna (np.: porządkująca wiele powiązanych tematów, aby łatwiej było między nimi nawigować)
Dane strukturalne
Można również specjalnie oznakować treść, nadać jej odpowiednią etykietę (korzystając z danych strukturalnych JSON-LD, schema.org) aby dostarczyć dodatkową informację, że ta strona zawiera np.: FAQ, artykuł, produkt, recenzję. Omówimy dokładniej czym są dane strukturalne w dalszej części artykułu.
Co widzi googlebot?
Warto też mieć na uwadze, że roboty Google nie widzą stron tak jak ludzie, nie odbierają ich w sposób jaki odbierają to ludzie, nie mają oczu, nie patrzą na ekran i nie analizują odbieranych bodźców tak jak ludzki mózg, jeszcze nie – i spokojnie, biorąc pod uwagę ilość danych i niedoskonałości ludzkiego mózgu raczej nigdy nie będą robić tego w ten sposób, raczej będą dążyć do bardziej algorytmicznego i optymalnego podejścia.
A więc co widzą roboty? W pierwszej kolejności widzą kod strony, kod HTML i to co umieszczamy w znacznikach i treść jaką na niej umieszczamy. Google podczas indeksacji również renderuje treść strony – czyli wykonuje skrypty na stronie tak jak to robi przeglądarka, żeby zobaczyć również dynamiczne elementy naszej strony. Po uwagę brane są również arkusze stylów CSS – można to stwierdzić po prostym fakcie, że Google potrafi w swoim rankingu potrafi ocenić to czy czy kontrast tła w stosunku do czcionki jest odpowiedni.
Następnie odpowiednie algorytmy NLP (Natural Language Processing) analizują znaczenie treści, powiedzmy że starają się zrozumieć język naturalny i jego intencje.
Jak sprawdzić czy strona się indeksuje?
Warto w tym miejscu rozróżnić widoczność od indeksowania. To, że strona znajduje się w indeksie, nie znaczy, że będzie widoczna, bo może znajdować się np.: na 10 stronie wyników wyszukiwania, więc techniczne będzie w indeksie, ale praktycznie nikt jej nigdy nie zauważy.
Operator wyszukiwania site i GSC stanowią podstawową analizę stanu indeksowania strony. Można używać dodatkowych narzędzie takich jak: Senuto (do analizy widoczności), Screaming Frog do wykonania crawla, czy SERanking do monitorowania strony. Jednak często i tak te narzędzia opierają się na integracji z Google Search Console.
A więc chcąc sprawić czy twoja strona jest w indeksie, lub jakie są powody jej odrzucenia zawsze twoim pierwszym kierunkiem będzie szybkie test w wyszukiwarce i Google Search Console.
Szybki test w wyszukiwarce
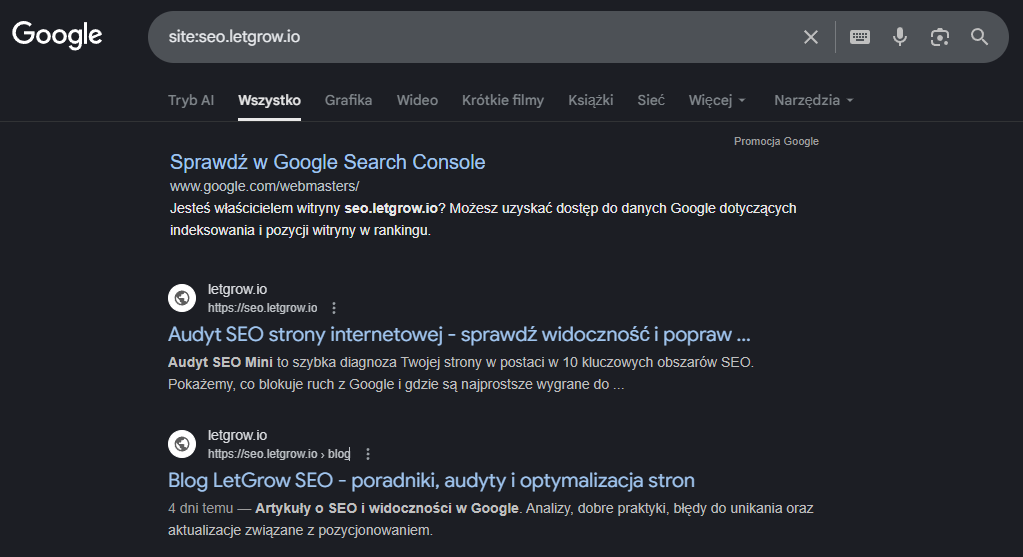
Jedną z prostszych opcji która pozwala na sprawdzenie obecności strony w indeksie jest użycie bezpośrednio w wyszukiwarce Google operatorów wyszukiwania (z ang. Search Operators) – dokładniej mówiąc zaawansowanych operatorów wyszukiwania.
Jak to zrobić? Wchodzimy w wyszukiwarkę Google i wpisujemy sekwencję: “site: <adres-strony>”
źródło: opracowanie własne
Ta opcja nie wymaga żadnych konfiguracji, ponoszenia kosztów ani użycia zewnętrznych narzędzi, można w ten sposób sprawdzić dowolną stronę. Dzięki temu widzisz również jak Google widzi twoją stronę, ale to nie gwarantuje pozycji – jest to raczej szybki test, nie narzędzie diagnostyczne.
Jeżeli nie widzisz swojej strony po tym teście to znaczy, że Google albo nie widzi twojej strony, jeszcze jej nie zaindeksował, albo już ją odwiedził ale uznał, że nie warto dodawać jej do indeksu. W takiej sytuacji następnym krokiem jest…
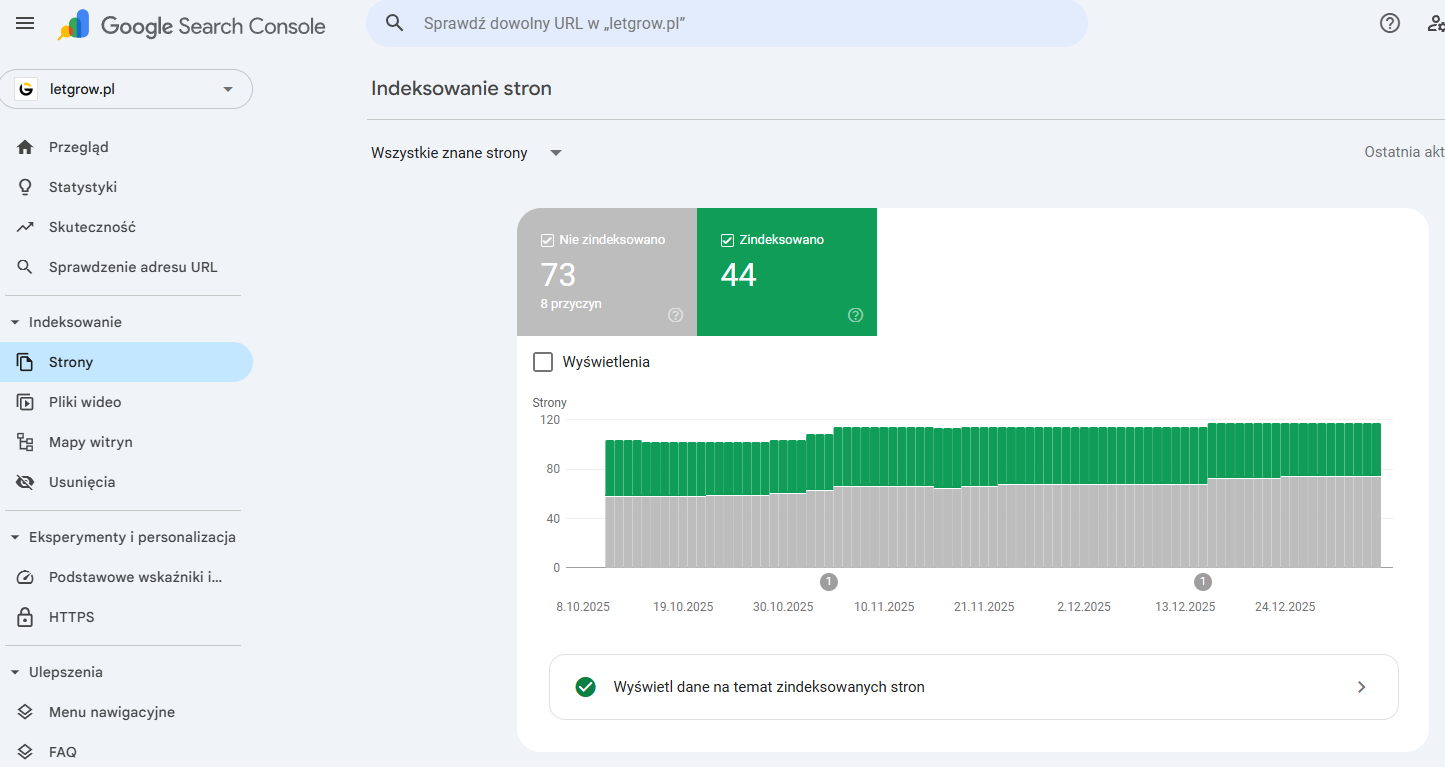
Sprawdzenie strony w Google Search Console
Jeżeli mamy podłączone GSC to w sekcji Indeksowanie -> strony możemy zobaczyć jakie strony są indeksowane, jakie strony Google odwiedził, jakie dodał do indeksu, a których nie dodał.
źródło: opracowanie własne
W Google Search Console, można również sprawdzić błędy i powody odrzuceń. Najważniejsze w tym momencie nie jest zgadywanie, tylko powód podany w GSC – bo inaczej naprawiasz blokadę (np. noindex), inaczej błąd serwera, a jeszcze inaczej duplikat.
Może się też zdarzyć, że strona jest, ale jakby jej nie było, Google indeksuje temat, ale wybrał inną wersję adresu (np. inną stronę kanoniczną albo wariant URL). Wtedy operator site: może pokazać inną wersję, a w GSC zobaczysz informację o duplikacie lub o tym, że Google wskazał inny kanoniczny URL.
Ile trwa indeksowanie i co wpływa na jego szybkość?
Nie wiadomo.
Tak, nie ma jednego gwarantowanego czasu, Google wprost komunikuje brak gwarancji crawlowania, indeksowania i wyświetlania strony w wynikach. (źródło: Szczegółowy przewodnik po działaniu wyszukiwarki Google). Google podaje ramy czasowe, ale dla odwiedzenia strony: od kilku dni do kilku tygodni i podkreśla, że prośba o indeksację nie oznacza, że strona trafi do wyników natychmiast (ani w ogóle).
Google opisuje też, że dla bardzo dużych i często aktualizowanych serwisów crawl budget ma znaczenie i wpływa na tempo odwiedzania URL-i.
W SEO często pojawia się pojęcie crawl budget (budżet crawlowania) – czyli jak często, Googlebot ma ochotę odwiedzać Twoje adresy URL. A wpływają na niego dwa składniki:
Dla małych stron temat zwykle nie jest krytyczny, ale przy większych serwisach (dużo podstron, parametry, filtry, duplikaty) budżet crawlowania potrafi tłumaczyć, dlaczego nowe lub zmienione strony czekają w kolejce, Google nie pomija ich złośliwie, Google musi priorytetyzować, co odwiedzi dziś, a co za tydzień.
W dokumencie „Ask Google to recrawl” jest wyraźnie zaznaczone, że systemy priorytetyzują szybką inkluzję treści wysokiej jakości więc można założyć, że przyłożenie się i przygotowanie treści wysokiej jakości treści zwiększy naszą szansę na pojawienie się w indeksie.
Szczera i brutalna opinia autora artykułu: Jeżeli ktoś gwarantuje konkretny czas to po prostu kłamie.
Na indeksowanie wpływa wiele czynników. Z wycieku algorytmu Google (o którym wspominaliśmy wcześniej), możemy przypuszczać, że są to tysiące odrębnych testów. Architektura systemu indeksującego strony, podszyta zaawansowanymi algorytmami, jest monumentalna i składa się z setek serwerów oraz dziesiątek programów (robotów – googlebot), które nieprzerwanie analizują niekończącą się kolejkę istniejących i nowych stron. A to zajmuje czas.
Aktualizacje i ponowne indeksowanie po zmianach
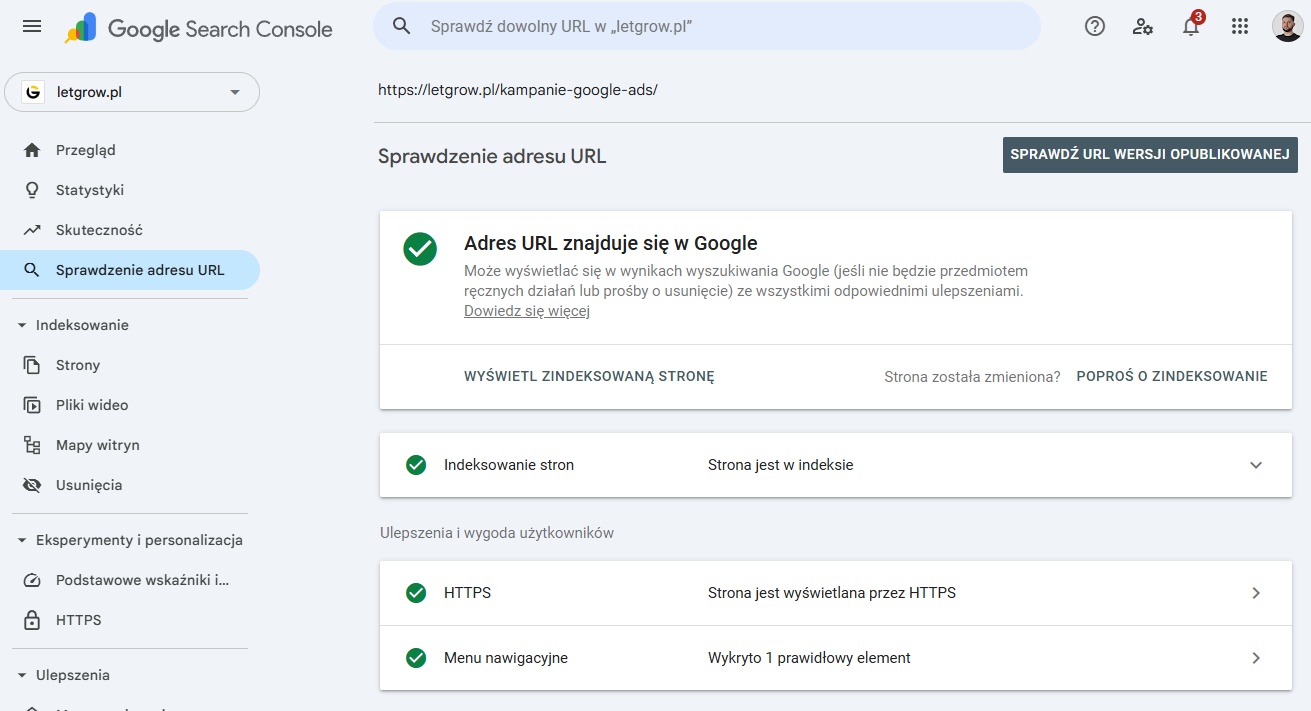
Dodatkowymi sygnałami pomagającymi Google w ponownym indeksowaniu jest aktualizacja atrybutu lastmod w mapie strony (sitemap.xml) i fakt, ze Google regularnie przegląda mapę strony.
Czym jest mapa strony? Tu niedługo pojawi się odnośnik do osobnego artykułu poświęconemu w pełni temu zagadnieniu. Prośmy o chwilę cierpliwosci.
Można również ręcznie poprosić Google o ponowne indeksowanie strony w Google Search Console (ale jak już wiemy, to nie daje gwarancji czy i kiedy strona zostanie zaindeksowana)
źródło: opracowanie własne
Dlaczego strona nie jest indeksowana?
Pierwszą rzeczą jaka zapewne przyjdzie Ci na myśl po poprzednim rozdziale jest to, że Google jeszcze nie dotarł na naszą stronę lub nasza strona czeka w kolejce do indeksowania. I będziesz mieć rację!
Think Content, brak znaczników i kanibalizacja
Jednym z aspektów wpływających na brak indeksowania lub długie oczekiwanie w kolejce jest nieprawidłowe przygotowanie treści – często strona ma słowa ale nie ma tematu i brakuje jej znaczników <title> czy <h1> określających temat.
Zdarza się też, że strona jest o dwóch (lub więcej) rzeczach na raz, brakuje głównego spajającego tematu. Lub dwie różne podstrony traktują o tym samym temacie, wtedy mówimy, że dochodzi do kanibalizacji treści. Google nie wie, która strona bardziej pasuje do tematu i wybiera jedną (lub co gorsza obie, ale traktuje je jako mniej ważne).
Niskiej jakości treść lub potocznie mówiąc tekst o niczym, tekst z nachalnie popychanym słowami kluczowymi, czy typowy tekst wygenerowany przez modele językowe takie jak ChatGPT, Gemini czy Claude często określamy jako Thin Content.
Bywa też tak, że Google przystępuje do analizy naszej strony, ale nic na niej nie widzi. Powodem takiego stanu rzeczy może być użycie specyficznej technologii do wyświetlania treści na stronie. Może się zdarzyć tak, że nasza strona jest przesyłana do przeglądarki w formie zaślepki, która w ułamku sekundy, niezauważalnym dla człowieka zostaje wypełniona treścią. Z naszej perspektywy nie ma różnicy czy ta treść tam była od razu czy została doczytana po chwil – wydarzyło się to tak szybko, że wymyka się to naszej percepcji. Ale nie wymyka się to percepcji Googlebot-a, działającemu podobnie jak przeglądarka, któremu została wysłana zaślepka nie zawierająca treści.
Jeżeli jesteś bardziej zaawansowany lub szerzej zainteresowany tematem SSR, zagadnieniem Headless i pokrewnych w dalszej części artykułu poświęciliśmy więcej uwagi tym zagadnieniom.
Za pustą lub szablonową stroną mogą również odpowiadać tzw. Archiwa WordPress, są to strony, które wyświetlają np.: listę wszystkich wpisów dla konkretnej kategorii. Domyślnie w WordPress, każda kategoria i każdy tag wpis ma swoją stronę archiwum. Warto o tym wiedzieć.
Problemy z dostępem i błędy techniczne
Czyli zamknięte drzwi. Google nie może wejść na stronę lub występują problemy techniczne skutecznie uniemożliwiają zobaczenie treści.
Poproś w wyszukiwarki o nieindeksowanie strony
Często przyczyną jest zostawienie “Poproś w wyszukiwarki o nieindeksowanie strony” w ustawieniach WordPress. W artykule A więc co to jest SEO? wyjaśniamy gdzie znaleźć tę opcję i jak to zmienić.
Kody błędów 403/404/500
Kody HTTP to odpowiedzi serwera na próbę wejścia na stronę. Gdy wchodzimy na stronę, tak naprawdę łączymy się do jakiegoś komputera gdzieś tam na świecie z prośbą o treść danej stron i ten komputern nam tę treść odsyła, ale odsyła także sporo dodatkowych informacji, jedną z nich jest status strony. Statusy dzielą się na rodziny, każda „setka” grupuje błędy o podobnej tematyce. W skrócie:
Gdy Googlebot próbuje wejść na stronę, działa jak zwykła przeglądarka, wysyła żądanie i oczekuje poprawnej odpowiedzi serwera. Jeśli zamiast treści dostaje kod błędu, indeksowanie zwykle zatrzymuje się na starcie.
Soft 404
Soft 404 to sytuacja, w której strona technicznie działa i zwraca kod 200 OK, czyli wszystko w porządku, ale z perspektywy Google wygląda jak strona nieistniejąca albo bezwartościowa bo wyświetla treść “Strona nie znaleziona”.
Noindex i X-Robots-Tag
Kolejna rzecz to Noindex i X-Robots-Tag, są to dwa sposoby przekazania wyszukiwarce tej samej informacji o tym aby nie pokazywać danej strony w wynikach wyszukiwania. Te dwa sposoby różnią się miejscem, w którym taka instrukcja jest umieszczana.
Noindex umieszcza się jako tag w kodzie HTML strony, w sekcji <head> (np. meta name=”robots” content=”noindex”). To rozwiązanie jest wygodne w CMS-ach (np. WordPress), bo zwykle da się je ustawić bez grzebania w bardziej zaawansowanych konfiguracjach ale działa wyłącznie dla stron HTML, dla innych zasobów, na przykład obrazków czy plików pdf nie zadziała.
X-Robots-Tag działa podobnie, tylko że nie jest wstawiany w HTML, tylko w nagłówek odpowiedzi serwera (np. X-Robots-Tag: noindex). Dzięki temu można nim objąć nie tylko strony, ale też pliki. I jest to bardziej zaawansowany sposób.
Jeśli strona była już w indeksie, dodanie noindex lub X-Robots-Tag najczęściej skutkuje usunięciem jej z wyników dopiero przy kolejnej wizycie robota.
Robots.txt
Plik robots.txt to prosty plik tekstowy dla robotów wyszukiwarek, umieszczony w głównym katalogu domeny (np. twojadomena.pl/robots.txt). W tym pliku można zdefiniować reguły, które na przykłąd będą określać jakie ścieżki na stronie robot może odwiedzać, a których ma nie skanować.
Strona osierocona
Strona osierocona to taka strona, do której nie istnieje żaden link, odnośnik, żadna nawigacja, żadne przekierowanie z całej witryny. Skoro my sami nigdzie nie kierujemy do takiej strony, to po co Google miałby ją dodawać do indeksu?
Historia domeny (rzadki ale bolesny przypadek)
Jeśli kupiłeś domenę z rynku wtórnego lub domenę, która wróciła do puli domen to może się zdarzyć, że trafisz na domenę z negatywną historią i mimo poprawnej konfiguracji Google konsekwentnie nie indeksuje serwisu (SEO-absurd). W takich przypadkach warto wziąć pod uwagę, że problem może leżeć nie w aktualnej wersji serwisu, tylko w historii domeny.
Domeny kupowane z rynku wtórnego potrafią mieć bagaż. Wcześniej mogły służyć do spamu, być zhakowane, przekierowywać na podejrzane miejsca albo publikować treści łamiące zasady. Efektem ubocznym może być taki, że nawet po zmianie właściciela domena może startować z gorszej pozycji zaufania (lub nawet być zbanowana czyli zablokowana przez Google), a część sygnałów z przeszłości ciągnie się za nią przez pewien czas.
Żeby zrozumieć, co było pod danym adresem wcześniej, najczęściej zagląda się do archiwum Internet Archive (Wayback Machine), które przechowuje historyczne migawki stron internetowych. Nie jest to dowód ostateczny (archiwum może mieć luki), ale bywa najszybszym sposobem, by zobaczyć, czy domena przez lata wyglądała jak normalny serwis, czy raczej jak coś, co mogło wpaść w konflikt z wyszukiwarką. Jeśli planujesz zakup domeny za więcej niż 9 zł. Warto rozważyć audyt domeny.
Nawet jeśli domena ma trudną historię, to nie jest wyrok na zawsze. Jednak bywa to przyczyną, która tłumaczy, dlaczego mimo sensownych działań Google nie indeksuje strony
Duplikacja i wersje URL http/https
Duplikacja w SEO bardzo często nie oznacza, że ktoś skopiował twój tekst, tylko coś prostszego:
Żeby temu zapobiegać, stosuje się kanonikalizację (z ang. conical), potocznie mówimy też canonicle (wym. [kanonikale]). Robi się to przez oznaczenie strony specjalną etykietą mówiącą Google, jaki jest jej właściwy, główny adres (tzw. canonical). Dzięki temu wyszukiwarka może zgrupować podobne wersje i traktować je jako jedną pozycję w indeksie.
Ten problem występuje szczególnie często w serwisach, gdzie łatwo tworzą się warianty adresów stosując parametry URL (np. sortowanie, filtrowanie) na przykład na stronach z listą produktów, paginacji bloga, a w WordPressie także archiwa kategorii, tagów, autorów.
W praktyce problem duplikacji często wygląda tak, że promujesz jeden adres, a Google indeksuje lub wyświetla inny. Może to też prowadzić do wykorzystania crawl-budget’u.

